该文章介绍了如何使用 NVIDIA cuTile 框架在 Blackwell 架构 GPU 上实现高性能矩阵乘法。环境要求包括 CUDA 13.1 以上、NVIDIA Blackwell(计算能力 10.x 与 12.x)以及 Python 3.10 以上。矩阵乘法被定义为 A(M×K) 与 B(K×N) 生成 C(M×N),核心计算为对 K 维度求和。cuTile 通过块级 Tile 编程,将输出矩阵划分为 (tm×tn) 的 Tile,每个 Block 负责一个 Tile,并在 K 维度上循环加载 (tm×tk) 与 (tk×tn) 子块进行累积。
在实现中,tm、tn、tk 被设为编译期常量,以启用循环展开和 Tensor Core 指令生成。Block 通过一维 grid 映射到二维 Tile 坐标,grid 大小为 ceil(m/tm)×ceil(n/tn)。在 float16 情况下,示例 Tile 配置为 tm=128、tn=256、tk=64。核心计算循环中,每个 Tile 使用 ct.mma() 完成矩阵乘加,累积器采用 float32 以保证数值稳定性,最终写回全局内存。
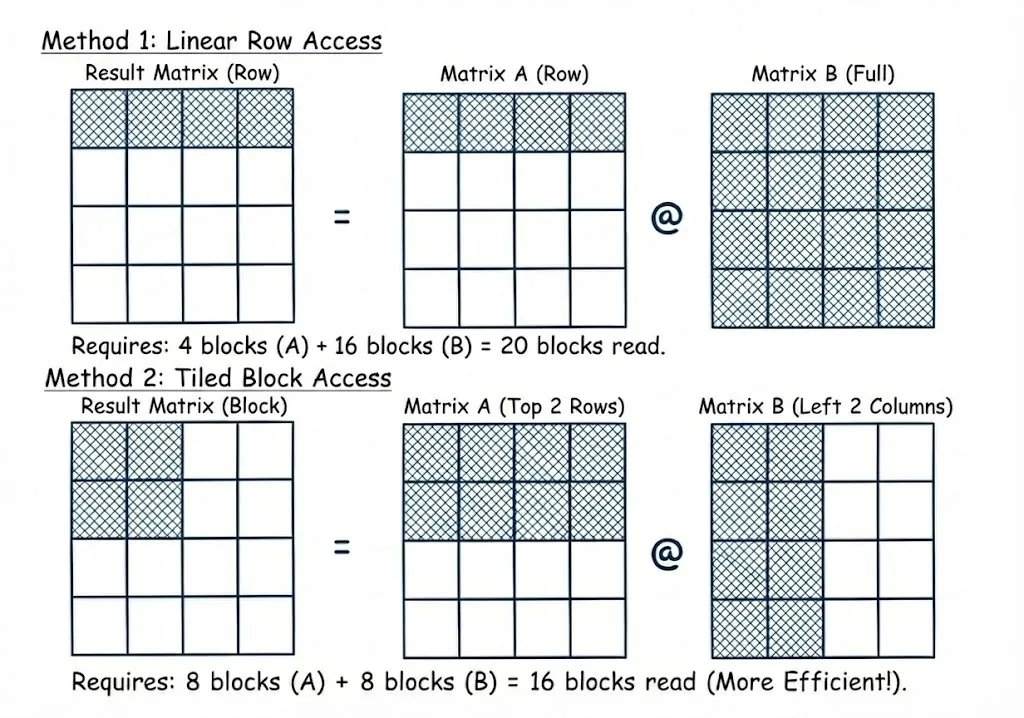
性能测试在 NVIDIA GeForce RTX 5080(计算能力 12.0)上完成,矩阵规模从 N=1024 到 16384(2¹⁰–2¹⁴)。通过 Tile 配置与 swizzle 优化,内存访问量可减少约 20%,显著提升缓存命中率。基准结果显示,在大矩阵下,cuTile 实现可达到 PyTorch/cuBLAS 性能的 90% 以上,验证了 Tile 编程在高性能 GPU 内核中的效率与可扩展性。
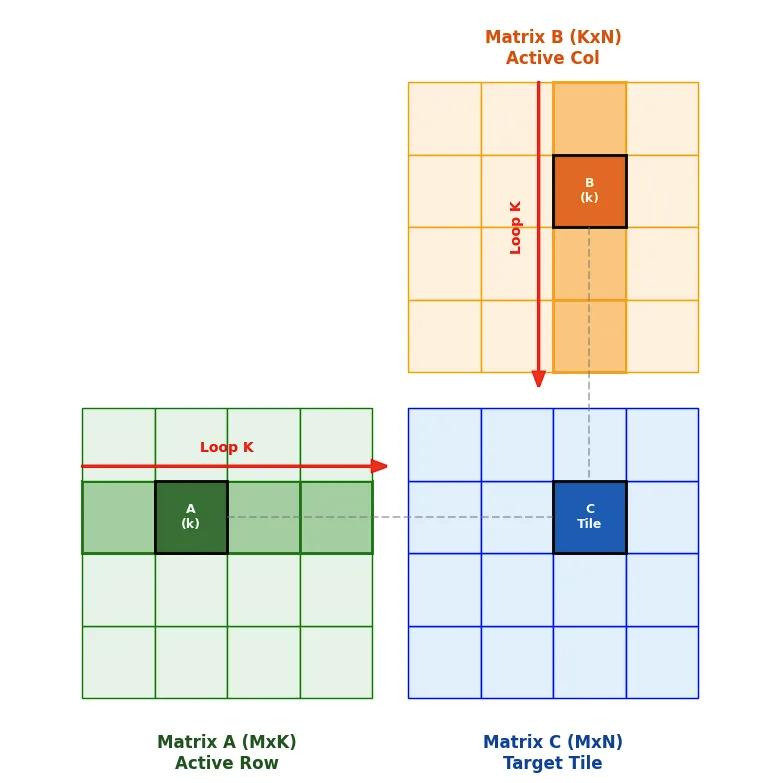
This article explains how to implement high-performance matrix multiplication using NVIDIA’s cuTile framework on Blackwell-architecture GPUs. The environment requires CUDA 13.1 or higher, NVIDIA Blackwell GPUs (compute capabilities 10.x and 12.x), and Python 3.10 or later. Matrix multiplication is defined as multiplying A(M×K) by B(K×N) to produce C(M×N), with computation summing over the K dimension. cuTile uses block-level Tile programming, dividing the output into (tm×tn) tiles, assigning one Block per tile, and iterating over K while loading (tm×tk) and (tk×tn) subtiles.
In the implementation, tm, tn, and tk are compile-time constants, enabling loop unrolling and Tensor Core instruction generation. Blocks are launched in a one-dimensional grid mapped to two-dimensional tile coordinates, with grid size equal to ceil(m/tm)×ceil(n/tn). For float16, the example configuration uses tm=128, tn=256, and tk=64. Inside the core loop, each tile uses ct.mma() for matrix multiply-accumulate, with a float32 accumulator for numerical stability before storing results back to global memory.
Performance was evaluated on an NVIDIA GeForce RTX 5080 (compute capability 12.0) using square matrices from N=1024 to 16384 (2¹⁰–2¹⁴). Swizzle-based tile mapping reduces memory accesses by about 20%, improving cache locality. Benchmark results show that for large matrices, the cuTile implementation achieves over 90% of PyTorch/cuBLAS performance, demonstrating the efficiency and scalability of Tile programming for high-performance GPU kernels.