在智谱于6月13日发布其迄今为止最强大的模型glm 5.2后,美中之间的人工智能竞争愈演愈烈。作为在Artificial Analysis上排名第一的开源模型以及整体排名第四的模型,glm 5.2仅落后于OpenAI的ChatGPT 5.5,并领先于谷歌的Gemini。该模型的发布恰逢特朗普政府禁止非美国用户使用Anthropic的Fable 5的一天之后,此禁令促使Anthropic停止了对海外用户的一切服务。通过公开其模型权重,且收费低于Fable 5的十分之一,智谱为那些寻求规避美国监管风险和不断攀升的AI成本的全球企业提供了一个极具吸引力的替代方案。
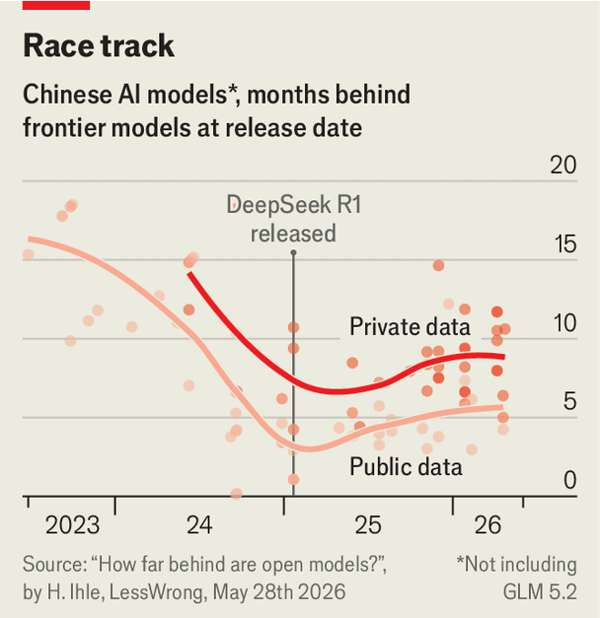
尽管该模型功能强大,但评估其实际性能显示美国依然保持着显著的领先优势。虽然公开基准测试表明中国仅落后四到六个月,但私有测试揭示了更宽泛的八到十个月的差距,因为中国模型往往存在“为考而教”的倾向。在特定的私有基准测试中,glm 5.2在Weirdml上落后七个月,在SimpleBench上则落后整整一年。在平均基准任务上,Fable 5仍比glm 5.2强约17%。尽管如此,glm 5.2在6月19日的一项办公任务测试中依然令观察家们感到惊讶,其表现超越了发布仅两个月的ChatGPT 5.5,表明美中差距并没有像预期的那样拉大。
此外,中国模型所宣称的成本优势因其低效率而大打折扣。尽管DeepSeek对v4模型每100万输出标记收费0.87美元,而Anthropic对Fable 5的同等服务收费50美元,但佐治亚理工学院的一项研究发现,DeepSeek在达成相同结果时使用的标记数量是OpenAI的23倍。在计入总标记使用量时,glm 5.2在软件工程基准测试中的实际花费超出了西方竞争对手。此外,由于先进芯片出口管制导致的算力短缺,中国实验室常面临服务中断,而美国对使用中国模型的本土企业所进行的监管审查也可能限制其采用。
The artificial intelligence race between the United States and China has intensified following Zhipu's June 13th release of glm 5.2, its most capable model to date. Ranking as the top open-source model and fourth overall on Artificial Analysis, glm 5.2 is positioned just behind OpenAI's ChatGPT 5.5 and ahead of Google's Gemini. Its launch occurred only one day after the Trump administration banned non-Americans from using Anthropic's Fable 5, prompting a total service shutdown for foreign users. By offering its model weights openly and charging less than one-tenth of the price of Fable 5, Zhipu provides an appealing alternative for global firms seeking to bypass American regulatory risks and escalating AI costs.
Despite the model's capabilities, evaluating its true performance reveals that the United States maintains a significant lead. While public benchmarks suggest China is only four to six months behind, private testing reveals a wider gap of eight to ten months, as Chinese models tend to "teach to the test." On specific private benchmarks, glm 5.2 lags by seven months on Weirdml and a full year on SimpleBench. Fable 5 remains roughly 17% more capable on average benchmark tasks. Nonetheless, glm 5.2 surprised observers on a June 19th office-task exam, outperforming the two-month-old ChatGPT 5.5, demonstrating that the gap is not widening as quickly as expected.
Furthermore, the supposed cost advantage of Chinese models is undermined by inefficiency. DeepSeek charges $0.87 per million output tokens compared to Anthropic's $50 for Fable 5, yet a Georgia Tech study found that DeepSeek used 23 times more tokens than OpenAI to achieve the same result. When total token usage is accounted for, glm 5.2 actually costs more than Western rivals on software-engineering benchmarks. Additionally, Chinese labs struggle with service delays due to compute shortages caused by advanced chip export controls, while American regulatory scrutiny of domestic firms using Chinese AI could limit its adoption.
Source: China is having another AI moment
Subtitle: A new model has narrowed the gap with America
Dateline: 6月 25, 2026 04:19 上午